- 머신러닝 알고리즘의 속도와 정확도를 높이는 범
- 이 이론들을 사이킷 런과 판다스 라이브러리에 적용하는 법
1.데이터 전처리
: 데이터를 그대로 사용하지 않고, 가공해서 모델을 학습시키는데 좀 더 좋은 형식으로 만들어 주는 것
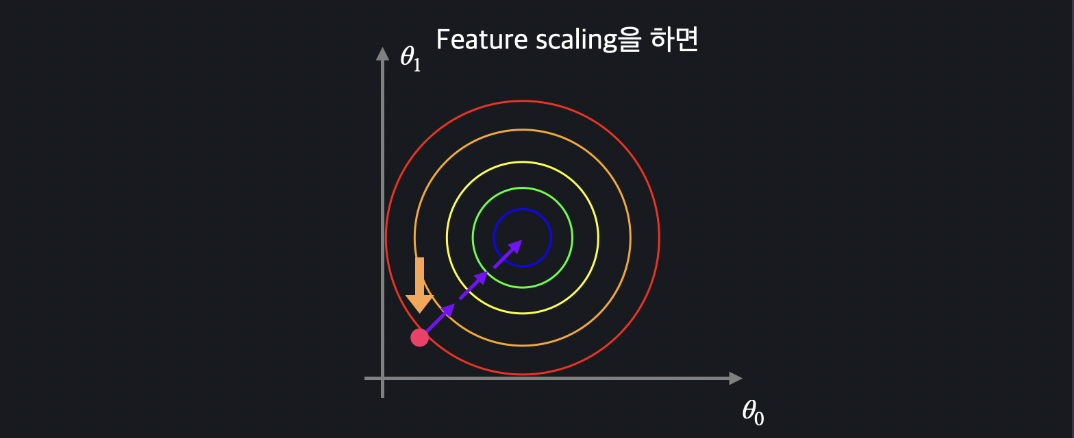
Feature Scaling
머신러닝 모델에 사용할 입력 변수들의 크기를 조정해서 일정 범위 내에 떨어지도록 바꾸는 것

--> 경사 하강법을 좀 더 빨리할 수 있게 도와 준다!
-(min-max) normalization
최솟값 최댓값을 이용해서 데이터의 크기를 0과 1 사이로 바꿔준다
경사하강법 (복습)
선형회귀: 데이터가 가장 잘 맞는 선 또는 가설 함수
손실함수: 가설함수를 평가하기 위한 함수, 손실이 크면 가설 함수가 안 좋다는 뜻이고 손실이 작으면 가설 함수가 좋다는 뜻이다.
선형회귀의 평균 제곱 오차가 크면 가설 함수가 안 좋고, 평균 제곱 오차가 작으면 가설 함수가 좋다
경사하강법: 어떤 지점에서 경사가 가장 가파른 방향으로 한 걸음 씩 내려가는 것. 그렇게 해서 최소점에 도달하는 것 .
등고선
3차원 그래프를 2차원으로 표현하는 방법
--> 특정 지점에서 경사가 가장 가파른 방향은 등고선과 수직이 되는 방향을 뜻함
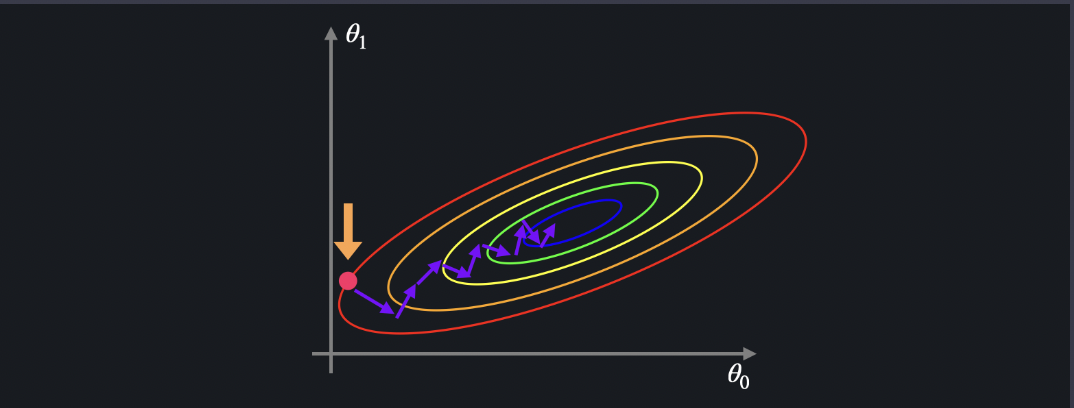
Feature Scaling & 경사 하강법
선형회귀에서는 데이터에 가장 적합한 선을 찾는 것이 목표이고 세타제로와 세타원을 찾아야 한다
세타원은 큰 영향을 주지 않지만 세타 원은 큰 변수와 곱해지기 때문에 조금만 바뀌어도 영향이 커진다
정규화
위 두 그래프를 경사하강시킴.
그래프는 경사하강을 통해서 지그재그모양으로 내려오게됨.
Standardiation
평균과 표준편차
표준화 (standardiation)
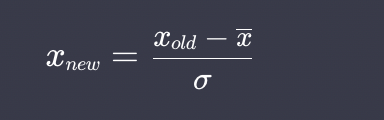
사이킷런으로 표준화하기
from sklearn import preprocessing
import pandas as pd
import numpy as np
NBA_FILE_PATH = '../datasets/NBA_player_of_the_week.csv'
# 소수점 5번째 자리까지만 출력되도록 설정
pd.set_option('display.float_format', lambda x: '%.5f' % x)
nba_player_of_the_week_df = pd.read_csv(NBA_FILE_PATH)
# 데이터를 standardize 함
scaler = preprocessing.StandardScaler()
standardized_data = scaler.fit_transform(height_weight_age_df)
standardized_df = pd.DataFrame(standardized_data, columns=['Height', 'Weight', 'Age'])minmaxscaler->standardscalar
머시러닝 데이터 종류
-수치형
-범주형
머신러닝 알고리즘은 수치형데이터여야 한다.
그렇다면 범주형을 수치형으로 어떻게 바꿔야 하는가?
'one-hot encoding'
02. 편향과 분산
편향
모델이 너무 간단해서 데이터의 관계를 잘 학습하지 못하는 경우 : 편향 (bias)가 높다
편향이 높은 모델은 선과 트레이닝 데이터의 관계가 명확하게 맞춰져 있다
하지만 편향이 낮다고 무조건 좋은 것은 아님
분산
데이터 셋 별로 모델이 얼마나 일관된 성능을 보여주는 지(variance)
데이터 셋 간에 성능 차이가 많이 나면 '분산이 높다'
직선 모델의 경우 분산이 작다
용어 정리
과소적합(underfit): 편향이 높고 분산이 낮은 모델
과적합(overfit): 편향이 낮고 분산이 높은 모델
편향-분산 트레이드 오프(bias-variance tradeoff)
일반적으로 편향과 분산 둘중 하나가 줄어들면 하나가 늘어나는 관계가 있다
그러므로 딱 적당한 곡선을 찾아야 한다.
머신러닝에서 정규화는 정규화항을 더해서 세타값들이 커지는 것을 방지하는 기법이다
.
.
.
K-겹 교차 겁증(k-fold cross validation)
: 머신러닝 성능을 좀 더 정확하게 평가 할 수 있는 방법
데이터를 training과 test로 나누어 서능파악
but 딱 test set에서만 성능이 좋은 거 일 수도 있고 , 안좋게 나올 수도 있다
K-겹 교차 검증
먼저 전체 데이터를 k개의 같은 사이즈로 나눈다.
이데이터셋들을 이용해서 모델의 성능을 여러번 검증
가장위에와 앞에 있는 데이터 셋을 테스트 셋 나머지를 트레이닝 셋으로 사용
K고르기
K는 데이터가 몇개 있느냐에 따라 다르지만 가장 일반적으로 사용하는 숫자는 5
그리고 데이터가 많을 수록 우연히 test set에서만 다르게 나올 확률이 적기 때문에 작은 k를 사용해도 됨
하이퍼 파라미터(hyperparameter)
많은 머신러닝 알고리즘에서 학습을 하기 전에 미리 정해 주어야 하는 변수 또는 파라미터들
그리드 서치(grid search)
굉장히 직관적 , 정해줘야 하는 각 하이퍼 파라미터에 넣어보고 싶은 후보 몇개씩 정하낟. 그리고 모든 후보 값의 조합으로 모델을 학습시켰을 때 성능이 가장 좋았던 하이퍼 파라미터 조합을 고르면 됨.